Model selection
Model Selection
모델 선택을 하기위해 여러가지 검증하는 법이 있다. 대표적인 Hold-out, k-fold cross validation, Nested cross-validation에 대해 언급한다. 그리고 최종적인 모델 평가를 교차행렬을 이용하여 내본다.
1) Hold-out

언더피팅과 오버피팅을 극복하기위해 데이터셋을 A와 같이 Training(70%)과 Test(30%)만 나누는 것이 아니라 B처럼 Training(40%), Validation(30%) 그리고 Test(30%)로 나눈다.
- Valid : 모델 개선 및 최종선택
- Test : 확정된 모델로 평가, 미래 예측에 대한 최종평가
2) K-fold cross validation
데이터 수가 적을 경우, hold-out방법으로 성능평가하는 것은 신뢰도가 떨어진다. 그래서 여러번 나눠서 모든데이터가 최소한번은 test로 쓰자라는 개념에서 나온 것이 k-fold crossvalidation이다.

k-fold crossvalidation은 전체 데이터를 k의 fold를 만들고 각 fold에 train과 test를 나누어 모델을 생성하게 된다. k는 대부분 5나 10을 사용하게되며 k=5일 경우, 총 5번 모델을 생성된다. 그림처럼 test는 그전에 사용된 것이 아닌 다른 것으로 진행된다. 최종평가(정확도)는 k개의 모델에서 나오는 test의 평균값으로 측정된다.
3) Grid Search : Nested cross-validation
Grid Search란 최적의 hyperparameter 조합 찾는 것을 말하며 검증할 때도 쓰인다. 바로 Nested cross-validation 이다.
- Nested cross-validation은 이전 교차검증을 중첩한 방식이다.
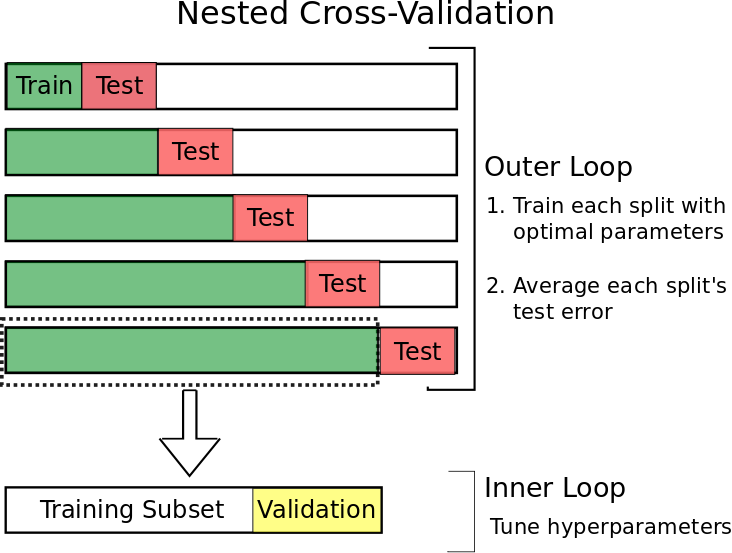
-
outer loop에서는 test set에 대한 평가를 진행하고 inner loop에서는 각 폴드의 최적 파라미터를 튜닝하는 것이다.
-
inner loop에서는 outer loop에 사용될 train set을 train subset과 validation set으로 분리하고 검증셋으로 평가하면서 파라미터를 튜닝합니다. 그렇게 나온 성능의 평균이 가장 좋은 하이퍼파라미터가 나올 거고 해당 최적의 파라미터를 통해 fold1에서 test set으로 평가합니다. 이러한 방식을 반복하는 방법
4) 모델평가(교차행렬)

- 위 표는 시험에 종종 출제되어 외웠던 기억이 많다. 그때 외웠던 방식이다.
- positive(긍정)으로 예측결과가 맞다라는 의미
- True란 예측과 실제와 맞다라는 의미
-
이 표를 통해 여러 평가를 할 수 있다.
- Acuuracy(정확도) : 맞게 검출한 비율
- $TP+TN \over TP+TN+FP+FN$
- 에러률: 1-정확도
- precision(정밀도): 맞다고 예측한 것중 실제 정답인 비율
- $TP\over TP+FP$
- Recall: 실제 정답이라고 했던 것중에 예측이 맞은 비율
- $TP\over TP+FN$
-
$F_1$ =$2TP\over 2TP+FP+FN$=$2precisionRecall\over precision+Recall$ (조화평균)
- 외울때 팁,
- precision은 p로 시작하니깐 positive와 prediction(예측)과 연관해서 예측이 맞은 것을 기준으로 정답 yes와 no를 다 쓴다라고 생각
- recall은 real로 실제 데이터다 라고 생각해서 정답이 yes기준으로 예측yes와 no를 다 쓴다고 생각
- Acuuracy(정확도) : 맞게 검출한 비율

댓글남기기