Cnn 기본개념
CNN(Convolutional Neural Network)
CNN이란? 딥러닝의 한종류로 이미지나 영상과 같은 데이터를 사용할때 많이 사용된다. 공부를 하면서 필수적으로 알아야하는 용어를 기준으로 정리한다.
1) 관련용어

- Filter (=Kernel) : 영역의 함수 필터링 기능
- 엄청헷갈렸던 부분인데, kernel의 깊이와 개수의 차이를 제대로 알고 가자!
- 깊이란? 하나의 커널이 몇개인지, 즉 (3x3x4) 4가 깊이
- 커널 개수? 커널 자체는 몇개인지, 커널(필터)가 2개
- 밑 그림에서 깊이는 3, 개수는 2개다

- 엄청헷갈렸던 부분인데, kernel의 깊이와 개수의 차이를 제대로 알고 가자!
- stride: Filter를 적용하기위한 이동간격 -> 클경우 size가 작아짐 (padding 도입)
- channel : output은 커널을 통해 나온 수, input채널수와 필터(커널)수는 같다. input에서 컬러일경우 보통 3.
-
output size:
- $N-Filter+2*padding\over stride$ + 1
- N: 원래 사이즈 , 결과는 정수로만

위 그림을 통해 input 이미지가 28x28x1이며 filter 3x3x6(커널 깊이:3x3의 필터가 6개로 쌓여있음)로 나오게되는 output (여기서는 feature map)은 26x26x6의 이미지로 나오게 된다. 26에 대한 계산은 filter를 거치게 되며 작아진 것이고 공식은 (28-3/1)+1이며 output size계산으로 한 결과이다. stride=1이고 padding=1 이므로 이런 결과가 나온다.
2) Zero Padding
-
목적: 입력이미지 크기 유지, 경계(모서리) 인식
-
zero padding이 필요한 사이즈 = $F-1\over2$
- F: filters of size F x F
- ex) F=5 -> zero pad with 2
3) Max-Pooling
- filter당 하나의 값만 추출 -> 그 중에 가장 큰 값을 적용
- 왜 max-pooling을 쓰나?
- 연산을 줄이기 위해(feature map 계수의 수를 줄이기 위해)
- 머신러닝 일반화해야해서 중요한 것만
- Average-Pooling
- 가장 큰값이 아니라 평균으로
- 장점: 위치에 대한 컨볼루션 계층의 과도한 민감도 완화
- pooling에서 입력 채널수 =출력채널수
4) cov layer의 parameter들 수 구하기
$W_c$ (conv-layer의 weight수) =$K^2$ (kernels width) X $C$(input 이미지 채널수) X $N$(kernel 수) $B_c$ =N $P_c$ =$W_c +B_c$
- 예시
| 사이즈 | 파라미터 수 | |
|---|---|---|
| input | 28x28x1 | |
| conv | 26x26x32 | $3^2$ x 1 x 32 + 32=320 |
| max-pooling | 13x13x32 | |
| conv | 11x11x64 | $3^2$ x 32 x 64 + 64=18496 |
| … | ||
| flatten | 576 | |
| dense1 | 64 | 576 x 64 + 64 |
| dense2 | 10 | 64 x 10 + 10 |
-
- 파라미터 수에서 filter=3인 이유
- F=N-Stride(outputsize-1) = 28-1(26-1) = 3
5) pre-trained
Transfer learning :외부모델을 나의 모델로 가져와서 학습
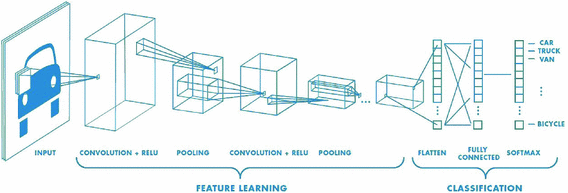
- convolutional base (이미지에서 일반적인 특징, 개념을 추출)
- densely connected classifier(모델이 훈련된 클래스 집합에 특유한 특성을 지님, 다른 문제에 적용시 재사용 어렵)
활용방법 :Feature extraction, Fine Tuning

(1) Feature extraction : pretrained convnet을 활용
- pre-trained network의 convolutional base를 활용하여 새로운 classifier학습
- Feature extraction(입력 데이터의 고유한 특징을 찾는 단계) $\rightarrow$ flattening $\rightarrow$ classification(찾아진 특성들을 가지고 class를 분류)
(2) Fine Tuning :후반부 more abstracted layer에 대한
- 이미 훈련된 네트워크에 사용자 지정 네트워크 추가
- Freeze (convolutional Base) +unfreeze(fine-tuning) $\rightarrow$추가한 부분 train
- pre-trained convnet의 tuning정도를 제한하기위해 learning rate 매우작게 설정
- 적은 양의 image dataset으로도 정확도 높은 예측 모델 생성가능
6) multiple input channels
 위 그림을 통해 커널이 1개라면, input(3x3x2) kernel (2x2x2) $\rightarrow$ output(2x2x1)
위 그림을 통해 커널이 1개라면, input(3x3x2) kernel (2x2x2) $\rightarrow$ output(2x2x1)
하지만 커널이 여러개라면 어떻게 될까?

- 앞에서 강조했듯이, input채널수와 각 커널깊이는 같아야해서 3이다.
-
output -> 커널개수가 2개면 output도 2개가 쌓임
torch.size([2,3,2,2]) kernel개수 :2, kernel깊이 :3, 사이즈 :2x2 ## 7) 1x1 cov layer - dnn 효과 ,Fully-connected layer
- weight수가 줄어들고 동일한 효과로 학습
- 계층사이의 채널 수를 조정하고 모델 복잡성을 제어하기 위해 사용
- 채널수 조정가능
- 많은 수의 비선형성 활성화 함수 사용하게 됨
8) LeNet-5 :1998년
구성
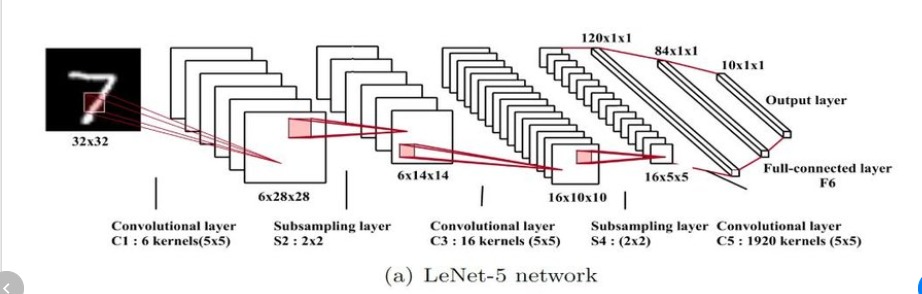
- convolutional : 2개 conv layer
- dense block: fully-connected(3개)
- 시그모이드, 평균 pooling사용

댓글남기기